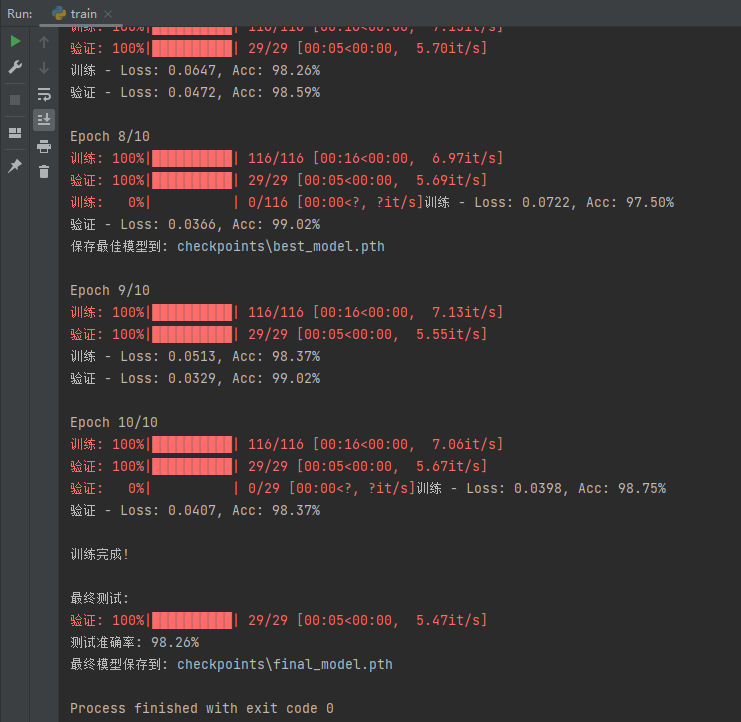
实际操作一下语音 brid 单词识别
第一步:定义一个函数
推荐使用了 DSCNN 神经网络
# 具体的网络结构
# models/ds_cnn.py
import torch.nn as nn
class DSCNN(nn.Module):
"""深度可分离卷积网络"""
def __init__(self, num_classes=4, input_channels=1):
super().__init__()
# 特征提取层
self.features = nn.Sequential(
# 标准卷积层
nn.Conv2d(input_channels, 64, kernel_size=(3, 3), stride=1, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2)),
# 深度可分离卷积层
nn.Conv2d(64, 64, kernel_size=(3, 3), groups=64, padding=1), # Depthwise
nn.Conv2d(64, 128, kernel_size=1), # Pointwise
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2)),
# 深度可分离卷积层
nn.Conv2d(128, 128, kernel_size=(3, 3), groups=128, padding=1),
nn.Conv2d(128, 256, kernel_size=1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2)),
)
# 分类器
self.classifier = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Dropout(0.3),
nn.Linear(256, 128),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(128, num_classes)
)
def forward(self, x):
x = self.features(x)
x = self.classifier(x)
return x第二步:定义一个 Loss
这个是一个分类问题,将一个读音分为是 brid、other、background 这几类,所以 Loss 使用 CrossEntropyLoss
criterion = nn.CrossEntropyLoss()第三步:Optimization
优化器引入 Adam
optimizer = optim.Adam(model.parameters(), lr=config['learning_rate'])开练,使用 backpropagation
def train_epoch(model, dataloader, criterion, optimizer, device):
"""训练一个epoch"""
model.train()
total_loss = 0
correct = 0
total = 0
for inputs, labels in tqdm(dataloader, desc="训练"):
inputs, labels = inputs.to(device), labels.to(device)
# 前向传播
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
# 反向传播
loss.backward()
optimizer.step()
# 统计
total_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
return total_loss / len(dataloader), 100. * correct / total