neo4j
neo4j
数据模型
属性图模型规则
表示节点,关系和属性中的数据
节点和关系都包含属性
关系连接节点
属性是键值对
节点用圆圈表示,关系用方向键表示。
关系具有方向:单向和双向。
每个关系包含“开始节点”或“从节点”和“到节点”或“结束节点”
Neo4j CQL 简单使用
创建节点
CREATE 命令
创建一个没有属性的节点
CREATE (<node-name>:<label-name>)语法说明
| 语法元素 | 描述 |
|---|---|
CREATE | 它是一个Neo4j CQL命令。 |
<node-name> | 它是我们要创建的节点名称。 |
<label-name> | 它是一个节点标签名称 |
创建具有属性的节点
CREATE (
<node-name>:<label-name>
{
<Property1-name>:<Property1-Value>,
........
<Propertyn-name>:<Propertyn-Value>
}
)语法说明:
| 语法元素 | 描述 |
|---|---|
<node-name> | 它是我们将要创建的节点名称。 |
<label-name> | 它是一个节点标签名称 |
<Property1-name>...<Propertyn-name> | 属性是键值对。 定义将分配给创建节点的属性的名称 |
<Property1-value>...<Propertyn-value> | 属性是键值对。 定义将分配给创建节点的属性的值 |
使用举例:
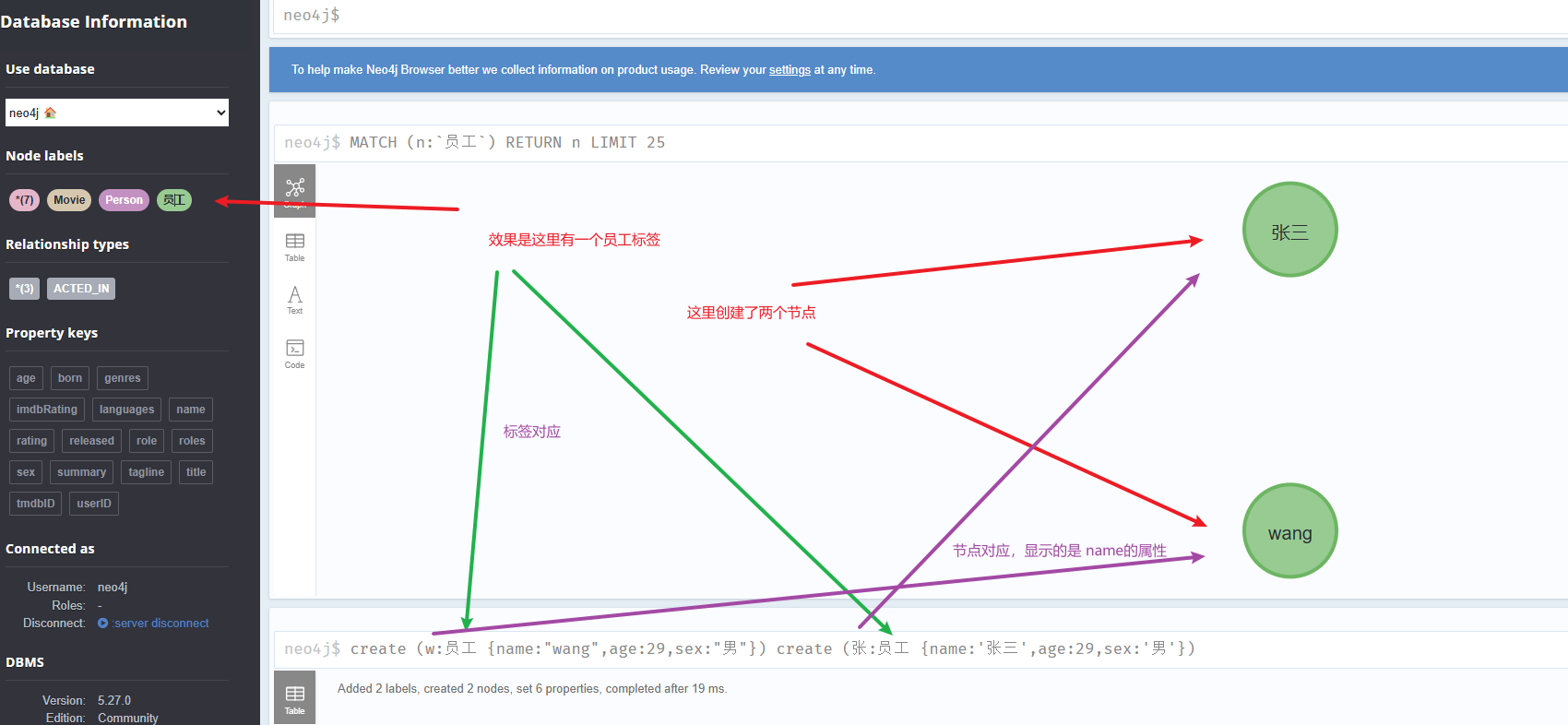
create (w:员工 {name:"wang",age:29,sex:"男"})
create (张:员工 {name:'张三',age:29,sex:'男'})注意:键值对的值如果是字符需要用双引号或单引号包裹

两个节点与数据模型的对应如下:
Neo4j 查询
不能单独使用MATCH或RETURN命令
CQL MATCH 命令
命令作用:
- 从数据库获取有关节点和属性的数据
- 从数据库获取有关节点,关系和属性的数据
命令语法:
MATCH
(
<node-name>:<label-name>
)语法说明
| 语法元素 | 描述 |
|---|---|
<node-name> | 这是我们要创建一个节点名称。 |
<label-name> | 这是一个节点的标签名称 |
| 注意事项 |
- Neo4j 数据库服务器使用此
<node-name>将此节点详细信息存储在 Database.As 中作为 Neo4j DBA 或 Developer,我们不能使用它来访问节点详细信息。 - Neo4j 数据库服务器创建一个
<label-name>作为内部节点名称的别名。作为 Neo4j DBA 或 Developer,我们应该使用此标签名称来访问节点详细信息。
使用 MATCH 命令需要配合 RETURN、等使用
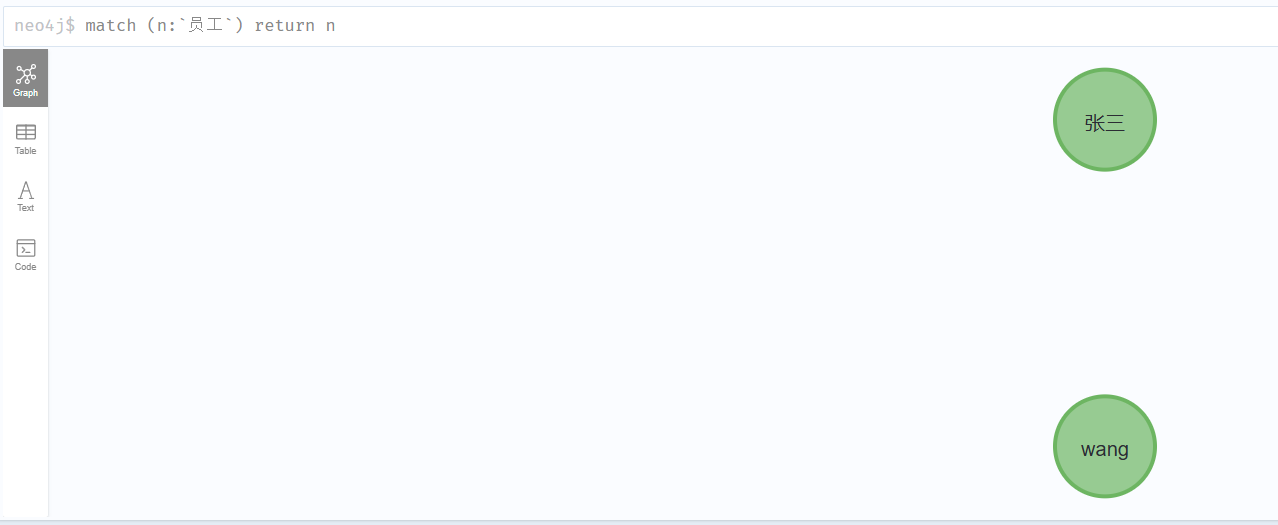
match (n:`员工` {name:'wang'}) return n
// 一个效果 使用where , where看下面where的使用,注意这里加 n.
match (n:`员工`) where n.name = 'wang' return n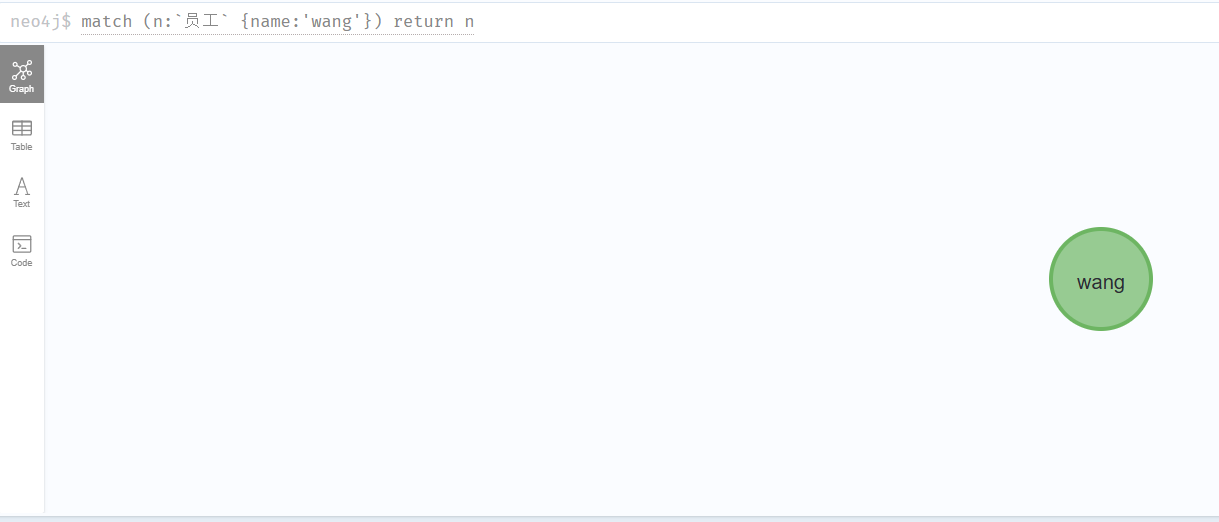
Neo4j CQL RETURN
Neo4j CQL RETURN子句用于
- 检索节点的某些属性
- 检索节点的所有属性
- 检索节点和关联关系的某些属性
- 检索节点和关联关系的所有属性
RETURN
<node-name>.<property1-name>,
........
<node-name>.<propertyn-name>语法说明:
| 语法元素 | 描述 |
|---|---|
<node-name> | 它是我们将要创建的节点名称。 |
<Property1-name>...<Propertyn-name> | 属性是键值对。 <Property-name>定义要分配给创建节点的属性的名称 |
不能单独使用RETURN子句。我们应该使用MATCH或CREATE命令。
联合使用
MATCH Command
RETURN Command使用示例
match(n:`员工`) return n.name,n.age
WHERE
-- 简单语法
WHERE <condition>
-- 复杂语法,使用布尔运算符在同一命令上放置多个条件
WHERE <condition> <boolean-operator> <condition>语法说明:
| 语法元素 | 描述 |
|---|---|
| WHERE | 它是一个Neo4j CQL关键字。 |
<property-name><属性名称> | 它是节点或关系的属性名称。 |
<comparison-operator> <比较运算符> | 它是Neo4j CQL比较运算符之一。请参考下一节查看Neo4j CQL中可用的比较运算符。 |
<value><值> | 它是一个字面值,如数字文字,字符串文字等。 |
Neo4j CQL中的布尔运算符
Neo4j支持以下布尔运算符在Neo4j CQL WHERE子句中使用以支持多个条件。
| 布尔运算符 | 描述 |
|---|---|
AND | 它是一个支持AND操作的Neo4j CQL关键字。 |
OR | 它是一个Neo4j CQL关键字来支持OR操作。 |
NOT | 它是一个Neo4j CQL关键字支持NOT操作。 |
XOR | 它是一个支持XOR操作的Neo4j CQL关键字。 |
使用示例:
match (n:`员工`) where n.name = 'wang' return n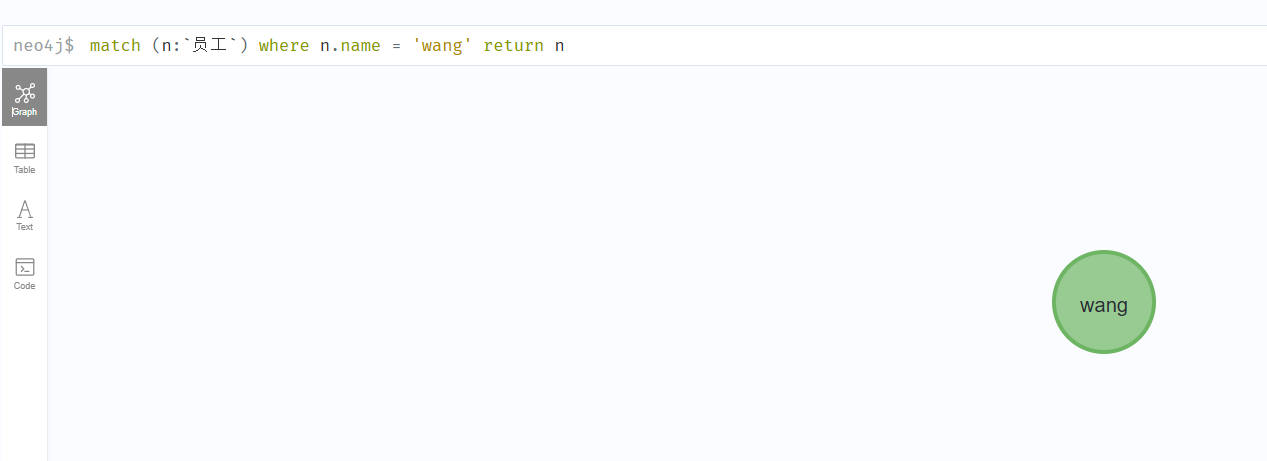
Neo4j CQL中的比较运算符
Neo4j 支持以下的比较运算符,在 Neo4j CQL WHERE 子句中使用来支持条件。
| 布尔运算符 | 描述 |
|---|---|
| = | 它是Neo4j CQL“等于”运算符。 |
<> | 它是一个Neo4j CQL“不等于”运算符。 |
< | 它是一个Neo4j CQL“小于”运算符。 |
> | 它是一个Neo4j CQL“大于”运算符。 |
<= | 它是一个Neo4j CQL“小于或等于”运算符。 |
>= | 它是一个Neo4j CQL“大于或等于”运算符。 |
NULL 值
创建一个节点不添加属性
create (li:`员工`)查询所有员工标签的节点
-- 我们能看到3个,第三个就是刚创建的li
match (n:`员工`) return n.name, n.age
-- 过滤没有NULL值的数据
match (n:`员工`) where n.name IS NOT NULL return n.name, n.age
-- 查找NULL值的数据
match (n:`员工`) where n.name IS NULL return n.name, n.age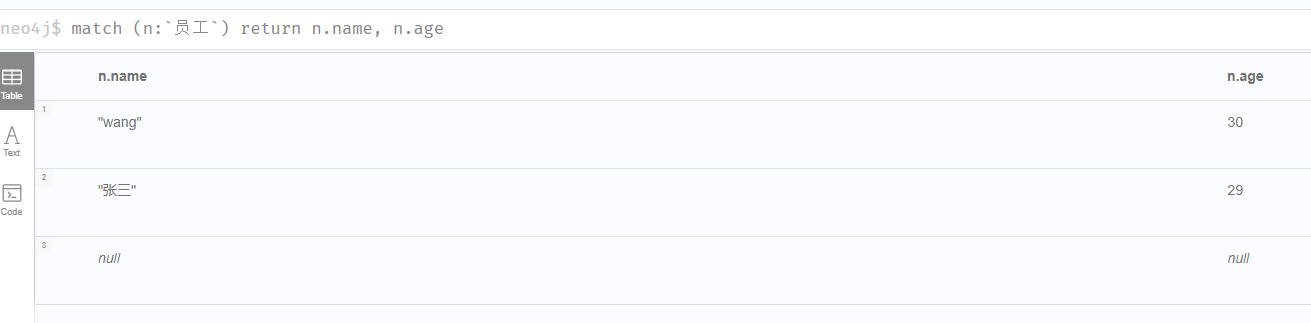
IN 操作符
-- 注意与 SQL 不一样这个里是方括号
match (n:`员工`) where n.name in ['wang', '张三'] return n.name, n.age
关系
语法:
CREATE (<node-name>:<label-name>)说明:
| 语法元素 | 描述 |
|---|---|
| CREATE 创建 | 它是一个Neo4j CQL关键字。 |
<node-name> <br><节点名称> | 它是一个节点的名称。 |
<label-name><br><br><标签名称> | 这是一个节点的标签名称。 |
现有节点创建的关系
两个现有节点:wang 和张三创建没有属性的关系。
MATCH (<node1-label-name>:<nodel-name>),(<node2-label-name>:<node2-name>)
CREATE
(<node1-label-name>)-[<relationship-label-name>:<relationship-name>{<define-properties-list>}]->(<node2-label-name>)
RETURN <relationship-label-name>语法说明:
| 语法元素 | 描述 |
|---|---|
| MATCH,CREATE,RETURN | 他们是Neo4J CQL关键字。 |
<node1-name> | 它用于创建关系的“From Node”的名称。 |
<node1-label-name> | 它用于创建关系的“From Node”的标签名称。 |
<node2-name> | 它用于创建关系的“To Node”的名称。 |
<node2-label-name> | 它用于创建关系的“To Node”的标签名称。 |
<relationship-name> | 这是一个关系的名称。 |
<relationship-label-name> | 它是一个关系的标签名称。 |
有属性
match (n1:`员工` {name:"wang"}), (n2:`员工` {name:"张三"}) create (n1) - [`关系标签`:`关系名称` {`关系属性1`:"aa",`关系属性2`:"bb"}] -> (n2)
如果我们按照例子的相同步骤创建从 张三 到 wang 的关系(那是相反的方向),那么我们将具有没有属性的双向关系与现有节点。
创建新节点和关系
CREATE
(<node1-label-name>:<node1-name>)-
[<relationship-label-name>:<relationship-name>]->
(<node1-label-name>:<node1-name>)
RETURN <relationship-label-name>语法说明:
| 语法元素 | 描述 |
|---|---|
| CREATE,RETURN | 他们是Neo4J CQL关键字。 |
<node1-name> | 它用于创建关系的“From Node”的名称。 |
<node1-label-name> | 它用于创建关系的“From Node”的标签名称。 |
<node2-name> | 它用于创建关系的“To Node”的名称。 |
<node2-label-name> | 它用于创建关系的“To Node”的标签名称。 |
<relationship-name> | 这是一个关系的名称。 |
<relationship-label-name> | 它是一个关系的标签名称。 |
使用示例:
create (w:`员工`) - [`关系标签`:`关系名称` {`关系属性1`:"aa",`关系属性2`:"bb"}] -> (张:`员工`)
-- 带上属性
create (w:`员工`{name:"wang",age:29,sex:"男"}) - [`关系标签`:`关系名称` {`关系属性1`:"aa",`关系属性2`:"bb"}] -> (张:`员工`{name:'张三',age:29,sex:'男'})检索关系节点的详细信息
// 只有一个 table 信息
match (a) - [r:`关系名称`] -> (b) return r
// 有 Graph 和 Table 信息
match (a) - [r:`关系名称`] -> (b) return r,a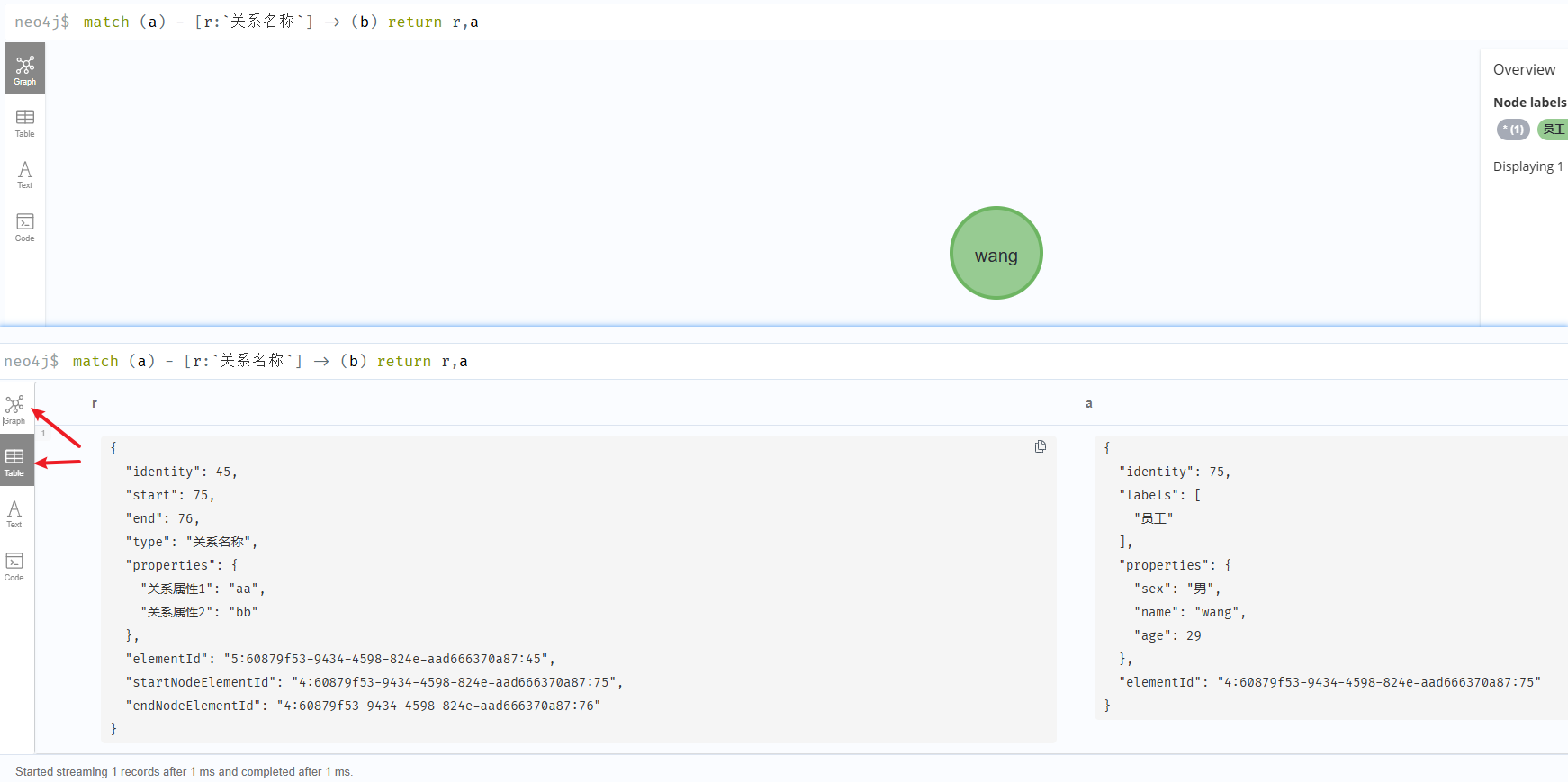
// 有 Graph 和 Table 信息
match (a) - [r:`关系名称`] -> (b) return r,a,b
删除
DELETE 删除
通过使用此命令,我们可以从数据库永久删除节点及其关联的属性。
DELETE <node-name-list>语法说明
| 语法元素 | 描述 |
|---|---|
| DELETE | 它是一个Neo4j CQL关键字。 |
<node-name-list> | 它是一个要从数据库中删除的节点名称列表。使用 , 分隔 |
| 使用示例: | |
直接删除有关系的节点会提示:Cannot delete node<77>, because it still has relationships. To delete this node, you must first delete its relationships. 即先删除关系 |
-- 执行下面报有关系必须先删除关系
match (n:`员工`) where n.name = 'wang' delete n
-- 找到关系
match (a) - [r:`关系名称`] -> (b) return r
-- 或者用这个
match (n:`员工` {name:'wang'}) - [r] -> (b:`员工` {name: '张三'}) return n,r,b
-- 将 return 换成 delete 即可删除
match (a) - [r:`关系名称`] -> (b) delete r
match (n:`员工` {name:'wang'}) - [r] -> (b:`员工` {name: '张三'}) delete n,r,bREMOVE 删除属性
REMOVE命令用于
- 删除节点或关系的标签
- 删除节点或关系的属性
使用示例:
match (n:`员工`) where n.name ='wang' remove n.age return n
match (n:Word) - [r] -> (a) where n.id = 1907620685213052929 and (a:Industry or a:Company) remove a.id return *DELETE和REMOVE命令之间的主要区别和相似性
DELETE和REMOVE命令之间的主要区别
- DELETE操作用于删除节点和关联关系。
- REMOVE操作用于删除标签和属性。
DELETE和REMOVE命令之间的相似性
- 这两个命令不应单独使用。
- 两个命令都应该与MATCH命令一起使用。
更新 SET 添加和更新属性
需要向现有节点或关系添加新属性。使用 SET 子句来执行以下操作。
- 向现有节点或关系添加新属性
- 添加或更新属性值
match (n:`员工`) where n.name ='wang' set n.age = 30 return n
排序 ORDER BY
ORDER BY <property-name-list> [DESC]语法说明:
| Syntax Element | Description |
|---|---|
| ORDER BY | 关键字 ORDER BY |
<property-name-list> | 需要排序的属性列表。标签名称.属性名称,逗号运算符分割 |
| DESC | 用于指定降序。可选 |
match (n:`员工`) return n.name,n.age order by n.age desc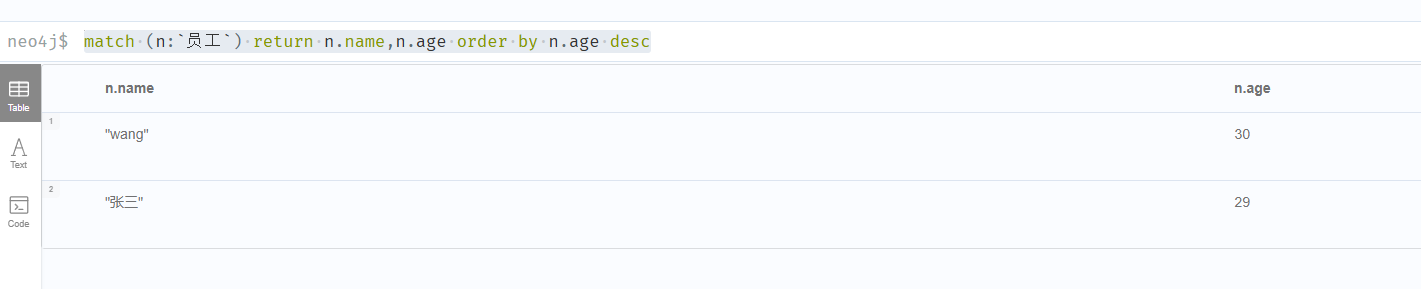
合并 UNION
与SQL一样,Neo4j CQL有两个子句,将两个不同的结果合并成一组结果
- UNION
- UNION ALL
UNION子句
它将两组结果中的公共行组合并返回到一组结果中。 它不从两个节点返回重复的行。
UNION ALL子句
它结合并返回两个结果集的所有行成一个单一的结果集。它还返回由两个节点重复行。
分页 LIMIT和SKIP
-- 上面排序的查询结果进行分页,这是第二页 skip 表示跳过节点个数 limit 表示限制返回1行
match (n:`员工`) return n.name,n.age order by n.age desc skip 1 limit 1
检查和创建合并的语法糖 MERGE
该命令检查该节点在数据库中是否可用。 如果它不存在,它创建新节点。 否则,它不创建新的。
MERGE命令
- 创建节点,关系和属性
- 为从数据库检索数据
MERGE命令是CREATE命令和MATCH命令的组合。
MERGE命令语法与CQL CREATE命令类似。
我们将使用这两个命令执行以下操作
- 创建具有一个属性的配置文件节点:Id,名称
- 创建具有相同属性的同一个Profile节点:Id,Name
- 检索所有Profile节点详细信息并观察结果
-- 可以看到跟 CREATE 一致 把关键词替换成 MERGE
MERGE (<node-name>:<label-name>
{
<Property1-name>:<Property1-Value>
.....
<Propertyn-name>:<Propertyn-Value>
})方向关系
在Neo4j中,两个节点之间的关系是有方向性的。 它们是单向或双向的。
由于Neo4j遵循属性图数据模型,它应该只支持方向关系。 如果我们尝试==创建==一个没有任何方向的关系,那么Neo4j DB服务器应该抛出一个错误。
CQL 函数
字符串函数列表
| 功能 | 描述 |
|---|---|
| UPPER | 它用于将所有字母更改为大写字母。 |
| LOWER | 它用于将所有字母改为小写字母。 |
| SUBSTRING | 它用于获取给定String的子字符串。 |
| REPLACE | 它用于替换一个字符串的子字符串。 |
聚合 AGGREGATION
Neo4j CQL提供了一些在RETURN子句中使用的聚合函数。 它类似于SQL中的GROUP BY子句。用在 RETURN 后的字段
聚合函数列表
| 聚集功能 | 描述 |
|---|---|
| COUNT | 它返回由MATCH命令返回的行数。 |
| MAX | 它从MATCH命令返回的一组行返回最大值。 |
| MIN | 它返回由MATCH命令返回的一组行的最小值。 |
| SUM | 它返回由MATCH命令返回的所有行的求和值。 |
| AVG | 它返回由MATCH命令返回的所有行的平均值。 |
关系函数
关系函数,以在获取开始节点,结束节点等细节时知道关系的细节。
关系函数列表
| 功能 | 描述 |
|---|---|
| STARTNODE | 它用于知道关系的开始节点。 |
| ENDNODE | 它用于知道关系的结束节点。 |
| ID | 它用于知道关系的ID。 |
| TYPE | 它用于知道字符串表示中的一个关系的TYPE。 |
-- <relationship-label-name>可以是来自Neo4j数据库的节点或关系的属性名称。
STARTNODE (<relationship-label-name>)
ENDNODE (<relationship-label-name>)使用示例:查看结束节点
match (a:`员工`) -[r:`关系名称`] -> (b:`员工`) return ENDNODE (r)
-- 查看关系类型
match (a:`员工`) -[r:`关系名称`] -> (b:`员工`) return TYPE (r)
索引
支持节点或关系属性上的索引,以提高应用程序的性能。
- Create Index 创建索引
- Drop Index 丢弃索引
创建索引的语法:
CREATE INDEX ON :<label_name> (<property_name>)
// 例如 3.x 版本
CREATE CONSTRAINT ON (c:Company) ASSERT c.name IS UNIQUEDrop Index语法:
DROP INDEX ON :<label_name> (<property_name>)UNIQUE 约束
像SQL一样,Neo4j数据库也支持对NODE或Relationship的属性的UNIQUE约束
UNIQUE约束的优点
- 避免重复记录。
- 强制执行数据完整性规则。
创建唯一约束语法
CREATE CONSTRAINT ON (<label_name>)
ASSERT <property_name> IS UNIQUE语法说明:
| 语法元素 | 描述 |
|---|---|
| CREATE CONSTRAINT ON | 它是一个Neo4j CQL关键字。 |
<label_name> | 它是节点或关系的标签名称。 |
| ASSERT | 它是一个Neo4j CQL关键字。 |
<property_name> | 它是节点或关系的属性名称。 |
| IS UNIQUE | 它是一个Neo4j CQL关键字,通知Neo4j数据库服务器创建一个唯一约束。 |
删除UNIQUE约束语法:
DROP CONSTRAINT ON (<label_name>) ASSERT <property_name> IS UNIQUE语法说明
| 语法元素 | 描述 |
|---|---|
| DROP CONSTRAINT ON | 它是一个Neo4j CQL关键字。 |
| <label_name> | 它是节点或关系的标签名称。 |
| ASSERT | 它是一个Neo4j CQL关键字。 |
| <property_name> | 它是节点或关系的属性名称。 |
| IS UNIQUE | 它是一个Neo4j CQL关键字,通知Neo4j数据库服务器创建一个唯一约束。 |
在数据库中,CONSTRAINT(约束) 是一种规则,用于确保数据的完整性和一致性。在 Neo4j 图数据库中,约束主要用于限制节点或关系的属性,防止无效或不符合逻辑的数据被写入。
Neo4j 中的常见约束类型
1. 唯一约束 (Unique Constraint)
作用:确保某个属性的值在特定标签的节点中唯一,避免重复。
示例:
-- Neo4j 4.x 语法 CREATE CONSTRAINT FOR (c:Company) REQUIRE c.name IS UNIQUE; -- Neo4j 3.x 语法 CREATE CONSTRAINT ON (c:Company) ASSERT c.name IS UNIQUE;用途:比如确保公司名称
Company.name不重复。
2. 存在性约束 (Existence Constraint)
作用:确保某个标签的节点或关系必须包含指定属性(属性值不能为
null)。示例:
-- Neo4j 4.x 语法 CREATE CONSTRAINT FOR (u:User) REQUIRE u.email IS NOT NULL; -- Neo4j 3.x 语法 CREATE CONSTRAINT ON (u:User) ASSERT EXISTS (u.email);用途:比如强制用户节点
User必须有email属性。
3. 键约束 (Key Constraint)
作用:确保某个标签的节点的一组属性组合唯一(Neo4j 5+ 支持)。
示例:
CREATE CONSTRAINT FOR (p:Product) REQUIRE (p.category, p.sku) IS UNIQUE;用途:比如商品的分类
category和库存编号sku组合必须唯一。
约束的核心作用
- 数据完整性:防止脏数据(如重复值、缺失关键属性)。
- 查询优化:唯一约束会自动创建索引,加速基于该属性的查询。
- 业务规则:强制符合业务逻辑(如用户必须填写邮箱)。
约束的使用场景
创建节点时自动校验:
CREATE (:User {name: "Alice", email: "alice@example.com"}); -- 成功(符合约束) CREATE (:User {name: "Bob"}); -- 失败(缺少 `email`,违反存在性约束)合并节点时避免重复:
MERGE (c:Company {name: "Neo4j"}); -- 依赖唯一约束确保唯一性批量导入数据前预校验:确保数据符合约束规则。
约束的操作命令
查看所有约束:
SHOW CONSTRAINTS;删除约束:
-- Neo4j 4.x
DROP CONSTRAINT constraint_name;
-- Neo4j 3.x
DROP CONSTRAINT ON (c:Company) ASSERT c.name IS UNIQUE;注意事项
- 版本兼容性:Neo4j 4.x 和 3.x 的约束语法不同(注意
FORvsON)。 - 数据预处理:创建约束前,确保现有数据满足约束条件,否则会失败。
- 性能影响:约束会略微增加写操作的开销,但能显著提升查询效率和数据质量。
示例:完整工作流
创建唯一约束:
CREATE CONSTRAINT FOR (c:Company) REQUIRE c.name IS UNIQUE;插入数据:
MERGE (c:Company {name: "Neo4j"}) ON CREATE SET c.created_at = timestamp();尝试插入重复数据:
CREATE (:Company {name: "Neo4j"}); -- 报错:违反唯一约束
Noe4j 常用使用场景
删除重复节点
造成场景:在插入是关系里加了唯一标识导致出现了多个边,使用删除 remove 移除了这个属性后发现会有相同名字的节点,需要将这样的节点删除。
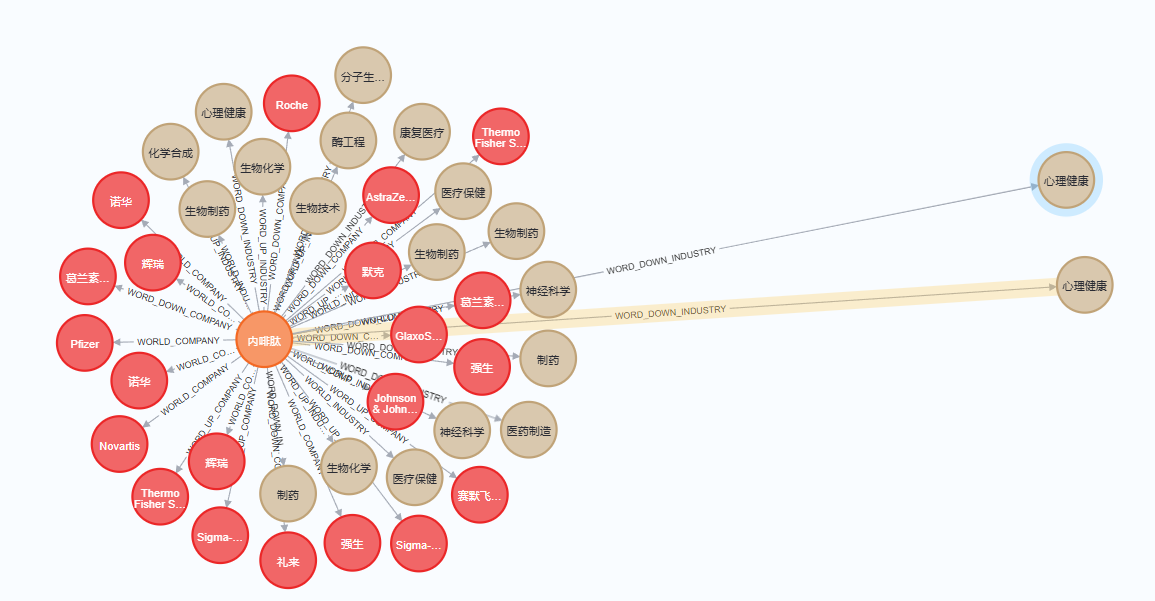
// 需要先找到这个样的点,才能删除
match (n:Word) - [r] -> (a) where n.id = 1907620685213052929 and (a:Industry or a:Company) with a.name as name, COUNT(*) as cnt where cnt > 1 return *这里可以在官网的 with 语法看到这个的详细使用:3.5版本 with 使用官网 、4.0 版本 with 使用官网
// 为了防止每次查询结果
MATCH (n) where n:Company or n:Industry or n:Product
WITH n.name AS name, n ORDER BY id(n)
WITH name, COLLECT(n) AS nodes
WHERE SIZE(nodes) > 1
UNWIND range(1, SIZE(nodes)-1) AS idx
DETACH DELETE nodes[idx]-
MATCH (n):匹配所有节点。 -
WITH ... ORDER BY id(n):按节点ID排序,确保每组第一个节点是ID最小的。 -
COLLECT(n) AS nodes:将同名的节点收集到列表中。 -
WHERE SIZE(nodes) > 1:筛选出具有重复name的分组。 -
UNWIND nodes[1:]:展开列表中第二个及之后的节点。 -
DETACH DELETE toDelete:删除这些节点及其所有关联关系。
删除两个节点的相同关系

步骤 1:定位重复关系
首先需要找到具有相同类型且连接同一对节点的多个关系。以下 Cypher 查询会按 起始节点、结束节点、关系类型 分组,筛选出重复的关系:
cypher
复制
MATCH (a)-[r]->(b)
WITH a, b, type(r) AS relType, collect(r) AS rels
WHERE size(rels) > 1
RETURN a, b, relType, rels步骤 2:删除重复关系(保留一个)
根据实际需求选择保留策略,以下是两种常见场景:
场景 1:保留第一个或最后一个关系(无属性依赖)
MATCH (a)-[r]->(b)
WITH a, b, type(r) AS relType, collect(r) AS rels
WHERE size(rels) > 1
UNWIND tail(rels) AS duplicate // 保留第一个,删除其余
DELETE duplicate或:
UNWIND rels[0..-1] AS duplicate // 保留最后一个,删除其余
DELETE duplicate场景 2:根据属性保留特定关系(例如最新时间戳)
如果关系有属性(如 createdAt),可以按属性排序后保留所需的一个:
MATCH (a)-[r]->(b)
WITH a, b, type(r) AS relType, r
ORDER BY r.createdAt DESC // 按时间倒序排列
WITH a, b, relType, collect(r) AS rels
WHERE size(rels) > 1
UNWIND tail(rels) AS duplicate
DELETE duplicate关键注意事项:
关系方向性:
- 上述查询默认处理 单向关系(如
A→B)。 - 如果双向关系(
A→B和B→A)需要去重,需调整查询逻辑。
- 上述查询默认处理 单向关系(如
属性依赖:
- 如果关系具有不同属性,需在
WITH或WHERE子句中明确判断重复的条件(例如忽略属性差异)。
- 如果关系具有不同属性,需在
数据安全:
- 先使用
RETURN检查要删除的关系,确认无误后再替换为DELETE。 - 使用
LIMIT分批处理,避免事务过大。
- 先使用
完整示例:
删除 User 节点之间重复的 FRIENDS 关系,保留创建时间最新的:
MATCH (a:User)-[r:FRIENDS]->(b:User)
WITH a, b, r
ORDER BY r.createdAt DESC
WITH a, b, collect(r) AS rels
WHERE size(rels) > 1
UNWIND tail(rels) AS duplicate
DELETE duplicate根据实际数据模型调整查询条件,确保操作前备份数据!