## Kettle-Java代码:分布式Id生成器
当使用Kettle导入数据到数据表时,由于使用的是MYSQL,所以自然而然想到使用增加序列对象去获取一个Id,但是经过测试这种方式非常慢。
分布式Id生成器
将以上 文章的代码打包成jar包,放到kettle/lib文件夹下。假设包名、类名:com.ibi.ptd.aps.core.utils.SnowflakeKeyGenerator.java
看文章,来打包jar
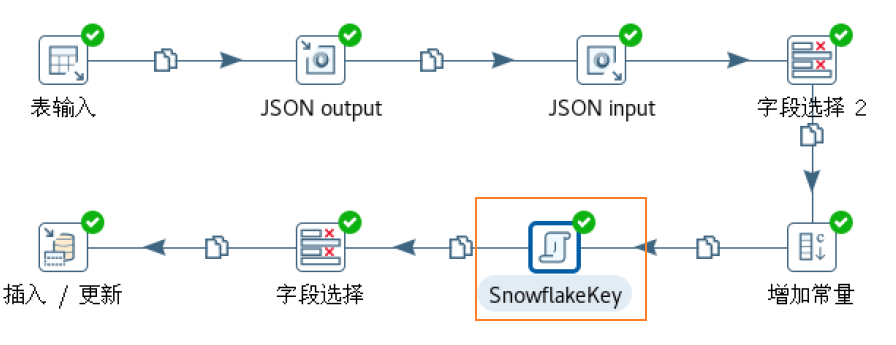
在这一步加上一个雪花ID
import java.lang.*;
// 一定要在这里初始化,不能在函数体里面,否则导致每处理一行记录,都会初始化一次生成器,从而导致会出现重复Id
import com.ibi.ptd.aps.core.utils.SnowflakeKeyGenerator;
SnowflakeKeyGenerator snowflake = new SnowflakeKeyGenerator(1);
public boolean processRow(StepMetaInterface smi, StepDataInterface sdi) throws KettleException{
// First, get a row from the default input hop
Object[] r = getRow();
// If the row object is null, we are done processing.
if (r == null) {
setOutputDone();
return false;
}
// Let's look up parameters only once for performance reason.
if (first) {
first=false;
}
// It is always safest to call createOutputRow() to ensure that your output row's Object[] is large
// enough to handle any new fields you are creating in this step.
Object[] outputRow = createOutputRow(r, data.outputRowMeta.size());
// 获取分布式 Id
String id = String.valueOf(snowflake.nextId());
// logBasic("id: " + id);
get(Fields.Out, "SNOWFLOW_ID_FEILD").setValue(outputRow, id);
// putRow will send the row on to the default output hop.
putRow(data.outputRowMeta, outputRow);
return true;
}